Техніки тестування чорної скриньки
Поділ на класи еквівалентності (версія 3.1)
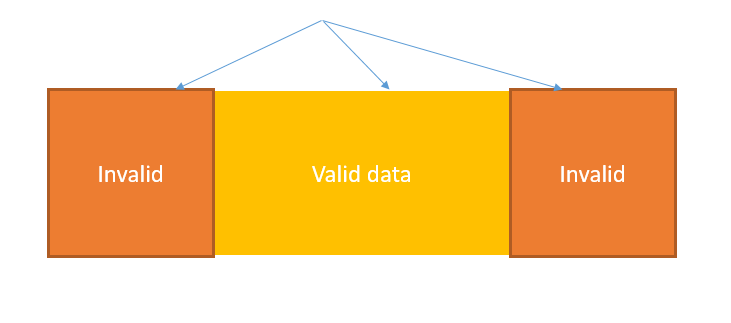
Поділ еквівалентності ділить дані на розділи (також відомі як класи еквівалентності) таким чином, щоб усі члени певного розділу оброблялися однаково. Існують розділи еквівалентності як для дійсних, так і для недійсних значень.
Дійсні значення – це значення, які повинні бути прийняті компонентом або системою. Розділ еквівалентності, що містить дійсні значення, називається «дійсним розділом еквівалентності».
Недійсні значення – це значення, які повинні бути відхилені компонентом або системою. Розділ еквівалентності, що містить недійсні значення, називається «недійсним розділом еквівалентності».
Розділи можна ідентифікувати для будь-якого елемента даних, пов’язаного з тестовим об’єктом, включаючи входи, виходи, внутрішні значення, значення, пов’язані з часом (наприклад, до або після події), а також для параметрів інтерфейсу (наприклад, інтегровані компоненти, що тестуються під час інтеграційного тестування).
Будь-який розділ можна розділити на підрозділи, якщо потрібно. Кожне значення має належати одному й лише одному розділу еквівалентності.
Якщо в тестових кейсах використовуються недійсні розділи еквівалентності, їх слід тестувати окремо, тобто не поєднувати з іншими недійсними розділами еквівалентності, щоб гарантувати, що помилки не маскуються. Збої можуть бути замасковані, коли кілька збоїв відбуваються одночасно, але лише один видимий, через що інші збої не виявляються.
Щоб досягти 100% покриття за допомогою цієї техніки, тестові кейси повинні охоплювати всі визначені розділи (включаючи недійсні розділи), використовуючи принаймні одне значення з кожного розділу. Покриття вимірюється як кількість розділів еквівалентності, перевірених принаймні одним значенням, поділена на загальну кількість визначених розділів еквівалентності, зазвичай виражену у відсотках. Поділ еквівалентності застосовується на всіх рівнях тестування.
Поділ на класи еквівалентності (версія 4.0)
Поділ еквівалентності ділить дані на розділи (відомі як розділи еквівалентності) на основі очікування, що всі елементи даного розділу будуть оброблятися об’єктом тестування однаково. Теорія, яка лежить в основі цієї техніки, полягає в тому, що якщо тестовий кейс, який перевіряє одне значення з розділу еквівалентності, виявляє дефект, цей дефект також має бути виявлений тестовими прикладами, які перевіряють будь-яке інше значення з того самого розділу. Тому достатньо одного тесту для кожного розділу.
Розділи еквівалентності можуть бути ідентифіковані для будь-якого елемента даних, пов’язаного з об’єктом тестування, включаючи входи, виходи, елементи конфігурації, внутрішні значення, значення, пов’язані з часом, і параметри інтерфейсу. Розділи можуть бути неперервними або дискретними, упорядкованими або невпорядкованими. Розділи не повинні перекриватися і повинні бути непорожніми наборами.
Для простих тестових об’єктів поділ на класи еквівалентності може бути легким, але на практиці розуміння того, як тестовий об’єкт оброблятиме різні значення, часто є складним. Тому до меж класів слід підходити обережно.
Розділ, що містить дійсні значення, називається дійсним розділом. Розділ, що містить недійсні значення, називається недійсним розділом. Визначення дійсних і недійсних значень можуть відрізнятися в різних командах і організаціях. Наприклад, дійсні значення можуть бути інтерпретовані як ті, які повинні бути оброблені тестовим об’єктом, або як ті, для яких специфікація визначає їх обробку. Недійсні значення можуть бути інтерпретовані як ті, які повинні бути проігноровані або відхилені тестовим об’єктом, або як такі, для яких у специфікації тестового об’єкта не визначена обробка.
У поділі на класи еквівалентності елементами покриття є розділи еквівалентності. Щоб досягти 100% охоплення за допомогою цієї методики, тестові випадки повинні перевіряти всі визначені розділи (включаючи недійсні розділи), покриваючи кожен розділ принаймні один раз. Покриття вимірюється як кількість розділів, виконаних принаймні одним тестовим випадком, поділена на загальну кількість ідентифікованих розділів і виражається у відсотках.
Багато тестових об’єктів включають кілька наборів розділів (наприклад, тестові об’єкти з більш ніж одним вхідним параметром), що означає, що тестовий приклад охоплюватиме розділи з різних наборів розділів. Найпростіший критерій покриття у випадку кількох наборів розділів називається покриттям кожного вибору (Ammann 2016). Кожне покриття вибору вимагає тестових кейсів для виконання кожного розділу з кожного набору розділів принаймні один раз. Кожне покриття вибору не враховує комбінації на межах класів.
Ілюстрація до поділу на класи еквівалентності
Отже спрощено, поділ на класи еквівалентності (Equivalence Partitioning) – це техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені для виконання елементів із розділів еквівалентності. У принципі, тестові випадки розроблені для покриття кожного розділу принаймні один раз.
Приклад тестового питання:

В цьому прикладі умовно можна виділити 5 класів еквівалентності і лише відповідь B) покриває всі визначені класи.
Аналіз граничних значень (версія 3.1)
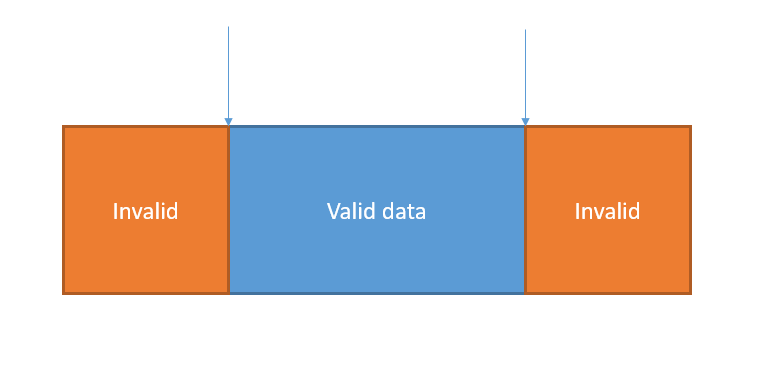
Аналіз граничних значень (BVA) є розширенням поділу на класи еквівалентності, але його можна використовувати лише тоді, коли розділ впорядкований і складається з числових або послідовних даних. Мінімальне та максимальне значення (або перше та останнє значення) розділу є його граничними значеннями.
Наприклад, припустімо, що поле введення приймає одне ціле значення як вхідні дані, використовуючи клавіатуру для обмеження введення таким чином, щоб неціле число було неможливим. Допустимий діапазон – від 1 до 5 включно. Отже, є три розділи еквівалентності: недійсний (занадто низький); дійсний; недійсний (занадто високий). Для дійсного розділу еквівалентності граничними значеннями є 1 і 5. Для недійсного (занадто високого) розділу граничне значення дорівнює 6. Для недійсного (занадто низького) розділу існує лише одне граничне значення, 0, оскільки це розділ лише з одним членом.
У наведеному вище прикладі ми визначаємо два граничні значення на межу. Межа між недійсним (занадто низьким) і дійсним дає тестові значення 0 і 1. Межа між дійсним і недійсним (занадто високим) дає тестові значення 5 і 6. Деякі варіанти цього методу визначають три граничні значення на межу: значення перед, біля та безпосередньо за межею. У попередньому прикладі з використанням трьохточкових граничних значень нижні граничні випробувальні значення становлять 0, 1 і 2, а верхні граничні випробувальні значення – 4, 5 і 6.
Поведінка на межах розділів еквівалентності, швидше за все, буде неправильною, ніж поведінка всередині розділів. Важливо пам’ятати, що як визначені, так і впроваджені межі можуть бути зміщені вище або нижче запланованих положень, можуть бути взагалі не встановлені або можуть бути доповнені небажаними додатковими межами. Аналіз і тестування граничних значень виявлять майже всі такі дефекти, змушуючи програмне забезпечення показувати поведінку з розділу, відмінного від того, до якого має належати граничне значення.
Аналіз граничних значень можна застосовувати на всіх рівнях тестування. Ця техніка зазвичай використовується для перевірки вимог, які вимагають діапазону чисел (включаючи дати та час). Граничне покриття для розділу вимірюється як кількість протестованих граничних значень, поділена на загальну кількість визначених граничних тестових значень, зазвичай виражених у відсотках.
Аналіз граничних значень (версія 4.0)
Аналіз граничних значень (BVA) — це техніка, яка базується на вивченні меж розділів еквівалентності. Тому BVA можна використовувати тільки для ситуацій, коли можна визначити межі. Мінімальне і максимальне значення розділу є його граничними значеннями. У випадку BVA, якщо два елементи належать до одного розділу, усі елементи між ними також повинні належати до цього розділу.
BVA зосереджується на граничних значеннях розділів, тому що розробники частіше помиляються з цими граничними значеннями. Типові дефекти, виявлені BVA, знаходяться там, де встановлені межі неправильно розташовані вище або нижче їх запланованих положень або взагалі не встановлені.
Цей навчальний сілабус охоплює дві версії BVA: 2-значний і 3-значний BVA. Вони відрізняються за елементами охоплення на межі, які необхідно використовувати для досягнення 100% покриття.
У BVA з двома значеннями (Craig 2002, Myers 2011) для кожного граничного значення є два елементи покриття: це граничне значення та його найближчий сусід, що належить до сусіднього розділу. Щоб досягти 100% покриття за допомогою 2-значного BVA, тестові випадки повинні використовувати всі елементи покриття, тобто всі визначені граничні значення.
Покриття вимірюється як кількість перевірених граничних значень, поділена на загальну кількість визначених граничних значень і виражається у відсотках.
У BVA з 3 значеннями (Koomen 2006, O’Regan 2019) для кожного граничного значення є три елементи покриття: це граничне значення та обидва його сусідні. Тому в 3-значному BVA деякі з елементів покриття можуть не бути граничними значеннями. Щоб досягти 100% охоплення за допомогою 3-значного BVA, тестові випадки повинні виконувати всі елементи охоплення, тобто визначені граничні значення та їхні сусіди. Покриття вимірюється як кількість використаних граничних значень та їхніх сусідів, поділена на загальну кількість визначених граничних значень та їхніх сусідів, і виражається у відсотках.
3-значний BVA є більш суворим, ніж 2-значний BVA, оскільки він може виявити дефекти, пропущені 2-значним BVA. Наприклад, якщо рішення «якщо (x ≤ 10) …» неправильно реалізовано як «якщо (x = 10) …», жодні тестові дані, отримані з 2-значного BVA (x = 10, x = 11), не можуть виявити дефект. Однак x = 9, отримане з 3-значного BVA, ймовірно, виявить це.
Ілюстрація аналізу граничних значень
Аналіз граничних значень (Boundary value analysis): Техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені на основі граничних значень.
Приклад тестового запитання:

В цьому прикладі правильною відповіддю є 33501, оскільки 4000+1500+28000 дає 33501. Отже, межі це 4000, 5500 і 33500. З наявних варіантів 33501 підпадає під техніку аналізу граничних значень.
Тестування таблиці рішень (версія 3.1)
Таблиці рішень є хорошим способом запису складних бізнес-правил, які система повинна реалізувати. Створюючи таблиці рішень, тестувальник визначає умови (часто входи) і кінцеві дії (часто виходи) системи. Вони утворюють рядки таблиці, зазвичай з умовами вгорі та діями внизу. Кожен стовпець відповідає правилу прийняття рішень, яке визначає унікальну комбінацію умов, що призводить до виконання дій, пов’язаних із цим правилом. Значення умов і дій зазвичай відображаються як логічні значення (істина чи хибність) або дискретні значення (наприклад, червоний, зелений, синій), але також можуть бути числами чи діапазонами чисел. Ці різні типи умов і дій можна знайти разом в одній таблиці.
Загальні позначення в таблицях рішень для умов такі:
- Y означає, що умова виконується (також може відображатися як T або 1)
- N означає, що умова хибна (також може відображатися як F або 0)
- — означає, що значення умови не має значення (також може відображатися як N/A) Для дій:
- X означає, що дія має відбутися (також може відображатися як Y, T або 1)
- Порожнє означає, що дія не повинна відбуватися (також може відображатися як – або N, або F, або 0)
Повна таблиця рішень містить достатню кількість стовпців (тестових кейсів), щоб охопити кожну комбінацію умов. Видаляючи стовпці, які не впливають на результат, можна значно зменшити кількість тестів. Наприклад, видаливши неможливі комбінації умов. Щоб отримати додаткові відомості про те, як згорнути таблиці рішень.
Загальний мінімальний стандарт охоплення для тестування таблиці рішень полягає в наявності принаймні одного тестового випадку на правило прийняття рішень у таблиці. Зазвичай це передбачає охоплення всіх комбінацій умов. Покриття вимірюється як кількість правил прийняття рішень, перевірених принаймні одним тестовим випадком, поділена на загальну кількість правил прийняття рішень, зазвичай виражених у відсотках.
Сильна сторона тестування таблиці рішень полягає в тому, що воно допомагає визначити всі важливі комбінації умов, деякі з яких інакше можна було б проігнорувати. Це також допомагає знайти прогалини у вимогах. Його можна застосовувати до всіх ситуацій, у яких поведінка програмного забезпечення залежить від комбінації умов, на будь-якому рівні тестування.
Тестування таблиці рішень (версія 4.0)
Таблиці рішень використовуються для перевірки виконання системних вимог, які визначають, як різні комбінації умов призводять до різних результатів. Таблиці рішень — це ефективний спосіб запису складної логіки, наприклад бізнес-правил.
При створенні таблиць рішень визначаються умови та результуючі дії системи. Вони утворюють рядки таблиці. Кожен стовпець відповідає правилу прийняття рішень, яке визначає унікальну комбінацію умов разом із відповідними діями. У таблицях рішень з обмеженим входом усі значення умов і дій (за винятком нерелевантних або нездійсненних; див. нижче) відображаються як логічні значення (істина або хибність). Крім того, у таблицях рішень із розширеним записом деякі або всі умови та дії також можуть мати кілька значень (наприклад, діапазони чисел, розділи еквівалентності, дискретні значення).
Умови позначаються наступним чином: «T» (true) означає, що умова виконана. «F» (false) означає, що умова не виконується. «–» означає, що значення умови не має значення для результату дії. «N/A» означає, що умова є нездійсненною для даного правила. Для дій: «X» означає, що дія має відбутися. Відсутнє значення означає, що дія не повинна відбуватися. Також можуть використовуватися інші позначення.
Повна таблиця рішень має достатню кількість стовпців, щоб охопити кожну комбінацію умов. Таблицю можна спростити, видаливши стовпці, що містять нездійсненні комбінації умов. Таблицю також можна згорнути, об’єднавши стовпці, у яких деякі умови не впливають на результат, в один стовпець. Алгоритми мінімізації таблиці рішень виходять за межі цієї навчальної програми.
У тестуванні таблиці рішень елементами покриття є стовпці, що містять можливі комбінації умов. Щоб досягти 100% охоплення за допомогою цієї методики, тестові випадки повинні використовувати всі ці стовпці. Покриття вимірюється як кількість використаних колонок, поділена на загальну кількість можливих колонок, і виражається у відсотках.
Сильна сторона тестування таблиці рішень полягає в тому, що воно забезпечує систематичний підхід до визначення всіх комбінацій умов, деякі з яких інакше можна було б проігнорувати. Це також допомагає знайти будь-які прогалини або протиріччя у вимогах. Якщо існує багато умов, виконання всіх правил прийняття рішень може зайняти багато часу, оскільки кількість правил експоненціально зростає разом із кількістю умов. У такому випадку, щоб зменшити кількість правил, які необхідно виконувати, можна використовувати мінімізовану таблицю рішень або підхід, заснований на оцінці ризику.
Ілюстрація тестування таблиці рішень
Тестування таблиці рішень (Decision Table Testing): Техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені для виконання комбінацій вхідних даних, показаних у таблиці рішень.
Приклад
Правила роботи:
- Кредит не надається безробітним
- Кредит надається особам, які мають постійну легальну роботу без обмежень
Вікові правила:
- Особам до 18 років кредит не надається
- Цільовою групою для отримання кредиту є люди 18-40 років
- Для осіб старше 40 років не надається
Правила доходу:
- Кредит не надається людям з доходом менше 1000 доларів США на місяць
- Кредит надається особам з доходом 1000-5000 USD/місяць, сума кредиту < 2000 USD
- Кредит надається людям з доходом понад 5000 доларів США на місяць, сума кредиту > 2000 доларів США
Результат поєднання правил видачі кредитів можна представити наступною таблицею:
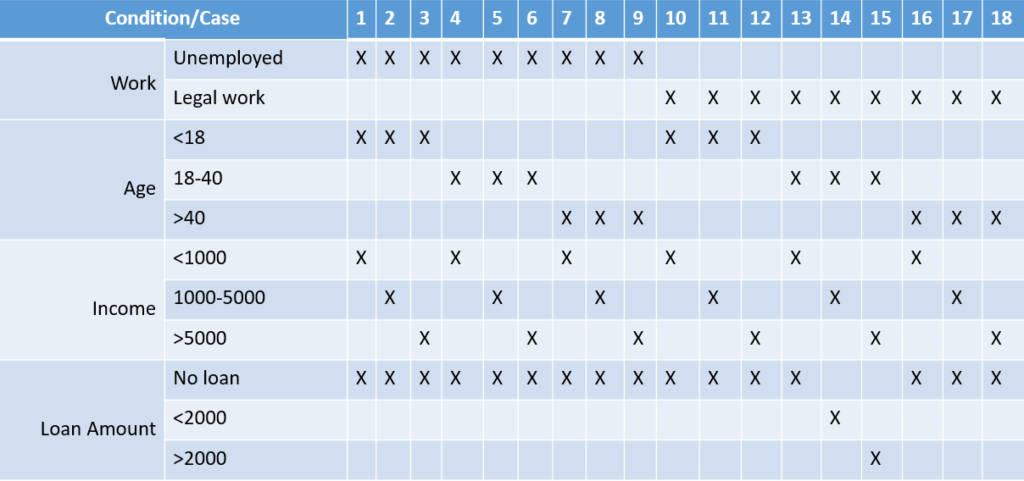
Як приклад можуть попросити визначити очікувані результати для наступних тест кейсів.
Test cases:
- Student, unemployed, 17 years old, income is 80 USD/month
- Post graduate, unemployed, 24 years old, no income
- Retired, unemployed, 62 years old, income is 200 USD/month
- Manager, legally employed, 50 years old, income 1500 USD/month
- Tester, legally employed, 40 years old, income 2000 USD/month
З наявних прикладів, кредит повинен бути наданий тільки по 5 тест кейсу. В усіх інших випадках у видачі кредиту повинно бути відмовлено.
Тестування переходу стану (верся 3.1)
Компоненти або системи можуть по-різному реагувати на подію залежно від поточних умов або попередньої історії (наприклад, подій, які відбулися після ініціалізації системи). Попередню історію можна підсумувати за допомогою поняття станів. Діаграма переходу станів показує можливі стани програмного забезпечення, а також те, як програмне забезпечення входить, виходить і переходить між станами. Перехід ініціюється подією (наприклад, введення користувачем значення в поле). Результатом події є перехід. Та сама подія може призвести до двох або більше різних переходів з одного стану. Зміна стану може призвести до того, що програмне забезпечення виконає певну дію (наприклад, виведе обчислення або повідомлення про помилку).
Таблиця переходів станів показує всі дійсні переходи та потенційно недійсні переходи між станами, а також події та результуючі дії для дійсних переходів. Діаграми переходів станів зазвичай показують лише дійсні переходи та виключають недійсні переходи.
Тести можуть бути розроблені для охоплення типової послідовності станів, для виконання всіх станів, для виконання кожного переходу, для виконання конкретних послідовностей переходів або для перевірки недійсних переходів.
Тестування переходу стану використовується для додатків на основі меню та широко використовується в галузі вбудованого програмного забезпечення. Техніка також підходить для моделювання бізнес-сценарію з певними станами або для тестування екранної навігації. Концепція стану є абстрактною – вона може представляти кілька рядків коду або цілий бізнес-процес.
Покриття зазвичай вимірюється як кількість ідентифікованих станів або переходів, що перевіряються, поділена на загальну кількість ідентифікованих станів або переходів у тестовому об’єкті, зазвичай виражену у відсотках. Для отримання додаткової інформації про критерії охоплення для тестування на перехід до стану.
Тестування переходу стану (версія 4.0)
Діаграма переходів станів моделює поведінку системи, показуючи її можливі стани та дійсні переходи станів. Перехід ініціюється подією, яка може бути додатково кваліфікована умовою захисту. Передбачається, що переходи відбуваються миттєво і іноді можуть призвести до виконання дій програмним забезпеченням. Загальний синтаксис маркування переходів такий: «подія [охоронна умова] / дія». Охоронні умови та дії можна пропустити, якщо вони не існують або не мають значення для тестувальника.
Таблиця станів — це модель, еквівалентна діаграмі переходів станів. Його рядки представляють стани, а стовпці представляють події (разом із умовами захисту, якщо вони існують). Записи таблиці (комірки) представляють переходи та містять цільовий стан, а також результуючі дії, якщо вони визначені. На відміну від діаграми переходів станів, таблиця станів явно показує недійсні переходи, які представлені порожніми комірками.
Тестовий приклад, заснований на діаграмі переходів станів або таблиці станів, зазвичай представляється як послідовність подій, що призводить до послідовності змін стану (і дій, якщо необхідно). Один тестовий приклад може охоплювати і зазвичай буде охоплювати кілька переходів між станами.
Існує багато критеріїв охоплення для тестування переходу на державний рівень. У цій програмі розглядаються три з них.
У всіх зонах покриття пунктами покриття є стани. Щоб досягти 100% покриття всіх станів, тестові кейси повинні гарантувати відвідування всіх станів. Покриття вимірюється як кількість відвіданих станів, поділена на загальну кількість станів і виражається у відсотках.
У покритті дійсних переходів елементи покриття є одними дійсними переходами. Щоб досягти 100% дійсного покриття переходів, тестові приклади повинні виконувати всі дійсні переходи. Покриття вимірюється як кількість здійснених дійсних переходів, поділена на загальну кількість дійсних переходів, і виражається у відсотках.
У покритті всіх переходів елементами покриття є всі переходи, показані в таблиці станів. Щоб досягти 100% покриття всіх переходів, тестові кейси повинні виконувати всі дійсні переходи та намагатися виконати недійсні переходи. Тестування лише одного недійсного переходу в одному тестовому кейсі допомагає уникнути маскування помилки, тобто ситуації, коли один дефект перешкоджає виявленню іншого. Покриття вимірюється як кількість дійсних і недійсних переходів, здійснених або спробованих охопити виконаними тестами, поділена на загальну кількість дійсних і недійсних переходів і виражається у відсотках.
Охоплення всіх станів слабше, ніж охоплення дійсних переходів, оскільки його зазвичай можна досягти без виконання всіх переходів. Дійсне покриття переходів є найбільш широко використовуваним критерієм покриття.
Досягнення повного дійсного покриття переходів гарантує повне покриття всіх станів. Досягнення повного охоплення всіх переходів гарантує як повне охоплення всіх станів, так і повне охоплення дійсних переходів і має бути мінімальною вимогою для критично важливого для безпеки програмного забезпечення.
Ілюстрація тестування переходу стану
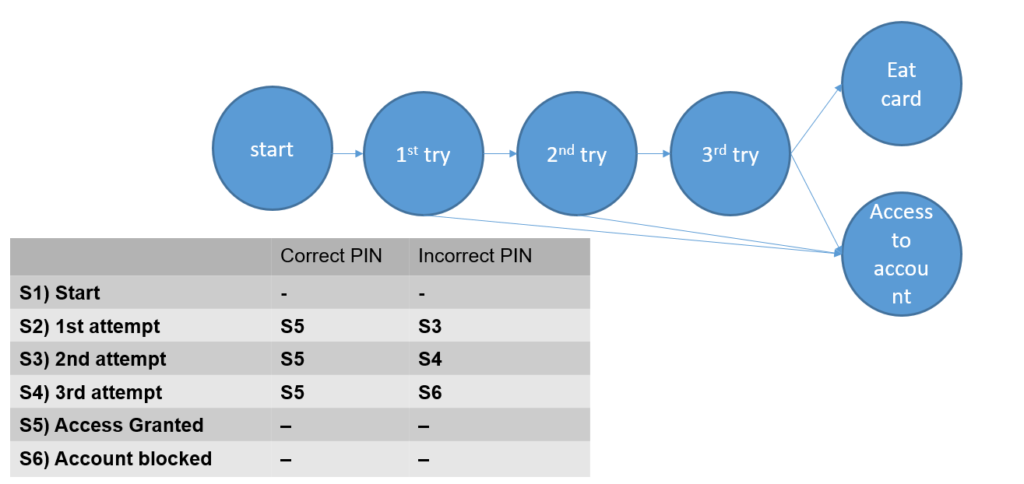
Популярний приклад для ілюстрації – переходи станів при спробі отримати доступ до свого рахунку в банкоматі. Три спроби для введення pin-коду, у разі введення неправильного коду тричі банкомат “з’їдає” картку. В цьому прикладі добре видно, що для тестування всіх станів достатньо буде двох тест кейсів.
Тестування варіантів використання (версія 3.1)
Тести можуть бути отримані з варіантів використання, які є особливим способом проєктування взаємодії з елементами програмного забезпечення. Вони містять вимоги до програмних функцій. Варіанти використання пов’язані з виконавцями (користувачами, зовнішнім апаратним забезпеченням або іншими компонентами чи системами) і суб’єктами (компонентом або системою, до якої застосовано варіант використання).
Кожен варіант використання визначає певну поведінку, яку суб’єкт може виконувати у співпраці з одним або кількома виконавцями (UML 2.5.1 2017). Випадок використання може бути описаний взаємодіями та діями, а також передумовами, постумовами та природною мовою, де це доречно. Взаємодія між виконавцями та суб’єктом може призвести до змін стану суб’єкта. Взаємодії можуть бути представлені графічно за допомогою робочих процесів, діаграм діяльності або моделей бізнес-процесів.
Варіант використання може включати можливі варіації його базової поведінки, включаючи виняткову поведінку та обробку помилок (відповідь системи та відновлення після помилок програмування, програми та зв’язку, наприклад, що призводить до повідомлення про помилку). Тести призначені для перевірки визначеної поведінки (основної, виняткової або альтернативної та обробки помилок). Охоплення можна виміряти кількістю протестованих варіантів використання, розділеною на загальну кількість варіантів поведінки, зазвичай виражену у відсотках.
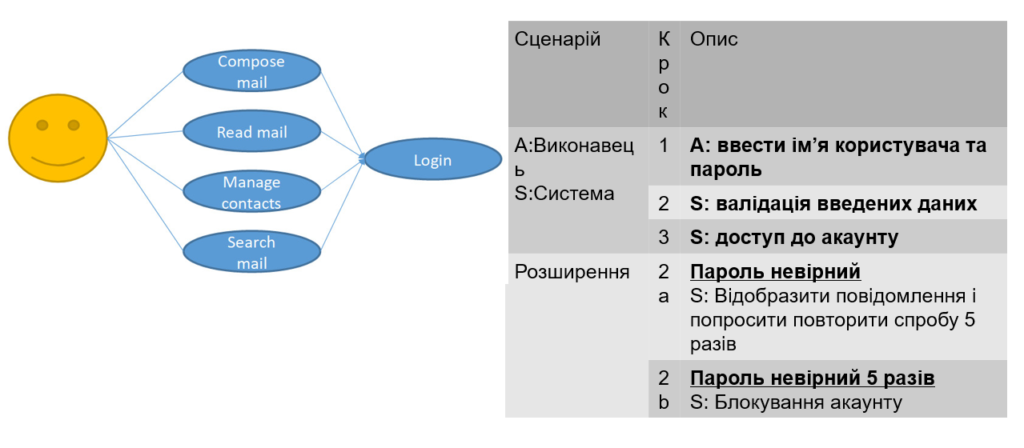
Теж популярний приклад ілюстрації тестування варіанітв використання (use case testing). Умовна система “Email” в якій користувач після логіну отримує доступ до своєї поштової скриньки і може писати листи, читати листи, керувати контактами, шукати листи. В таблиці представлені сценарії для логіну.
В цьому відео починаємо працювати з секцією 4.2.
00:00:34 Equivalence Partitioning
00:18:26 Boundary Value Analysis
00:42:14 Приклади EP/BVA
00:58:37 Decision Table Testing
01:17:24 Приклад Decision Table Testing
01:30:31 State Transition Testing
01:57:23 Use case testing