Техніки тестування засновані на співпраці (версія 4.0)
Кожен із методів тестування має певну мету щодо виявлення дефектів. З іншого боку, підходи, засновані на співпраці, зосереджуються також на уникненні дефектів шляхом співпраці та спілкування.
Спільне написання історії користувача (версія 4.0)
Історія користувача представляє функцію, яка буде цінною для користувача або покупця системи чи програмного забезпечення. Історії користувачів мають три важливі аспекти (Jeffries 2000), які разом називаються «3 C»:
Картка (Card) – засіб опису історії користувача (наприклад, індексна картка, запис на електронній дошці)
Розмова (Conversation) – пояснює, як використовуватиметься програмне забезпечення (може бути задокументовано або усно)
Підтвердження (Confirmation) – критерії прийняття
Найпоширеніший формат історії користувача: «Як [роль], я хочу [досягнути мети], щоб я міг [результивна бізнес-цінність ролі]», а потім критерії прийняття.
Спільне авторство історії користувача може використовувати такі методи, як «мозковий штурм» і розумового пов’язування (mind mapping). Співпраця дозволяє команді отримати спільне бачення того, що має бути надано, беручи до уваги три точки зору: бізнес, розробка та тестування.
Хороші історії користувачів мають бути: незалежними, такими, що підлягають обговоренню, цінними, такими, що підлягають оцінці, невеликими та перевіреними (INVEST). Якщо зацікавлена сторона не знає, як перевірити історію користувача, це може означати, що історія користувача недостатньо зрозуміла, або що вона не відображає чогось цінного для них, або що зацікавленій стороні просто потрібна допомога в тестуванні (Wake 2003).
Приймальні критерії (версія 4.0)
Приймальні критерії для історії користувача — це умови, яким має відповідати реалізація історії користувача, щоб бути прийнятою зацікавленими сторонами. З цієї точки зору, приймальні критерії можна розглядати як умови тестування, які повинні виконуватися тестами. Критерії прийняття зазвичай є результатом спілкування.
Критерії прийнятності використовуються для:
Визначення обсягу історії користувача
Досягнення консенсусу серед зацікавлених сторін
Опису як позитивних, так і негативних сценаріїв
Слугують як основа для перевірки прийнятності історії користувача
Дозволяють точне планування та оцінку
Є кілька способів написати критерії прийняття для історії користувача. Два найпоширеніші формати:
Орієнтований на сценарій (наприклад, формат Given/When/Then, що використовується в BDD)
Орієнтований на правила (наприклад, список перевірки маркерів або таблична форма відображення введення-виведення)
Більшість критеріїв прийнятності можна задокументувати в одному з цих двох форматів. Однак команда може використовувати інший, спеціальний формат, якщо критерії прийнятності чітко визначені та однозначні.
Розробка керована приймальним тестуванням –Acceptance Test-driven Development (ATDD)
ATDD — це підхід, який передбачає спочатку тестування. Тестові кейси створюються до впровадження історії користувача. Тестові кейси створюють члени команди з різними точками зору, наприклад, клієнти, розробники та тестувальники (Adzic 2009). Тестові кейси можуть виконуватися вручну або автоматизовано.
Першим кроком є специфікаційний семінар, де члени команди аналізують, обговорюють і пишуть історію користувача та (якщо ще не визначено) її критерії прийнятності. Під час цього процесу вирішуються проблеми неповноти, двозначності або розв’язуються дефекти в історії користувача. Наступним кроком є створення тестових кейсів. Це може робити як команда в цілому, так і тестувальник окремо. Тестові кейси базуються на критеріях прийнятності та можуть розглядатися як приклади того, як працює програмне забезпечення. Це допоможе команді правильно реалізувати історію користувача.
Оскільки приклади та тести однакові, ці терміни часто використовуються як синоніми. Під час планування тесту можна застосовувати інші методи тестування.
Як правило, перші тестові кейси є позитивними, підтверджують правильну поведінку без винятків або умов помилки та включають послідовність дій, які виконуються, якщо все йде, як очікувалося. Після того, як позитивні тести зроблені, команда повинна провести негативне тестування. Нарешті, команда також повинна охоплювати нефункціональні характеристики якості (наприклад, ефективність продуктивності, зручність використання). Тестові кейси мають бути виражені у спосіб, зрозумілий для зацікавлених сторін. Як правило, тестові кейси містять речення природною мовою, що включають необхідні попередні умови (якщо такі є), вхідні дані та постумови.
Тестові кейси повинні охоплювати всі характеристики історії користувача і не повинні виходити за межі історії. Однак критерії прийнятності можуть деталізувати деякі проблеми, описані в історії користувача. Крім того, два тести не повинні описувати однакові характеристики історії користувача.
Коли вони записуються у форматі, який підтримується інфраструктурою автоматизації тестування, розробники можуть автоматизувати тестові випадки, написавши допоміжний код під час реалізації функції, описаної в історії користувача. Після цього приймальні випробування стають вимогами до виконання.
ISTQB Certified Tester Foundation Level. Курс для початківців. Секція 4.5.
В цьому відео починаємо працювати з секцією 4.5. 00:00:41 Collaboration-based Test Approaches 00:01:45 Collaborative User Story Writing 00:07:11 Acceptance Criteria 00:10:59 Acceptance Test-driven Development (ATDD)
Техніки тестування засновані на досвіді (версія 3.1)
При застосуванні методів тестування, заснованих на досвіді, тестові кейси створюються на основі навичок та інтуїції тестувальника, а також його досвіду роботи з подібними програмами та технологіями. Ці методи можуть бути корисними для виявлення тестів, які нелегко ідентифікувати за допомогою інших більш систематичних методів. Залежно від підходу та досвіду тестувальника, ці методи можуть досягти різного ступеня охоплення та ефективності. Покриття може бути важко оцінити, і його неможливо виміряти за допомогою цих методів.
Техніки тестування засновані на досвіді (версія 4.0)
До цих технік відносять:
Вгадування помилок
Дослідницьке тестування
Тестування на основі контрольного списку
Вгадування помилок (версія 3.1)
Вгадування помилок — це техніка, яка використовується для передбачення появи помилок, дефектів і збоїв на основі знань тестувальника, зокрема:
Як програма працювала в минулому
Якого роду помилки, як правило, допускаються
Збої, які виникли в інших програмах
Методичний підхід до техніки вгадування помилок полягає у створенні списку можливих помилок, дефектів і збоїв, а також проєктних тестів, які виявлятимуть ці збої та дефекти, які їх спричинили. Ці списки помилок, дефектів і несправностей можна створити на основі досвіду, даних про дефекти та збої або загальновідомих причин збою програмного забезпечення.
Вгадування помилок (версія 4.0)
Вгадування помилок — це техніка, яка використовується для передбачення появи помилок, дефектів і збоїв на основі знань тестувальника, зокрема:
Як програма працювала в минулому
Типи помилок, які зазвичай допускають розробники, і типи дефектів, які є результатом цих помилок
Типи збоїв, які виникли в інших подібних програмах
Загалом помилки, дефекти та збої можуть бути пов’язані з: введенням (наприклад, правильний вхід не приймається, параметри неправильні або відсутні), виводом (наприклад, неправильний формат, неправильний результат), логікою (наприклад, відсутні випадки, неправильний оператор), обчислення (наприклад, неправильний операнд, неправильне обчислення), інтерфейси (наприклад, невідповідність параметрів, несумісні типи) або дані (наприклад, неправильна ініціалізація, неправильний тип).
Полювання на помилки – це методичний підхід до впровадження вгадування помилок. Ця техніка вимагає від тестувальника створити або отримати список можливих помилок, дефектів і збоїв, а також розробити тести, які ідентифікуватимуть дефекти, пов’язані з помилками, виявлятимуть дефекти або викликатимуть збої. Ці списки можна створювати на основі досвіду, даних про дефекти та збої або загальновідомих причин збою програмного забезпечення.
Дослідницьке тестування (версія 3.1)
У дослідницькому тестуванні неформальні (не визначені заздалегідь) тести розробляються, виконуються, реєструються та динамічно оцінюються під час виконання тесту. Результати тестування використовуються, щоб дізнатися більше про компонент або систему, а також створити тести для областей, які можуть потребувати додаткового тестування.
Дослідницьке тестування іноді проводиться за допомогою сеансового тестування для структурування діяльності. Під час сеансового тестування дослідницьке тестування проводиться протягом певного періоду часу, і тестувальник використовує чартер тестування, який містить цілі тестування, щоб керувати тестуванням. Тестувальник може використовувати аркуші тестового сеансу, щоб задокументувати виконані кроки та зроблені відкриття.
Дослідницьке тестування є найбільш корисним, коли є мало або неадекватні специфікації або значний тиск часу на тестування. Дослідницьке тестування також корисно як доповнення до інших більш формальних методів тестування.
Дослідницьке тестування тісно пов’язане зі стратегіями реактивного тестування. Дослідницьке тестування може включати використання інших методів чорного скриньки, білого скриньки та методів, заснованих на досвіді.
Дослідницьке тестування (версія 4.0)
У дослідницькому тестуванні тести одночасно розробляються, виконуються та оцінюються, поки тестувальник досліджує об’єкт тестування. Тестування використовується, щоб дізнатися більше про тестовий об’єкт, глибше вивчити його за допомогою цілеспрямованих тестів і створити тести для неперевірених областей.
Дослідницьке тестування іноді проводиться за допомогою сеансового тестування для структурування. У підході, заснованому на сеансах, дослідницьке тестування проводиться в межах визначеного періоду часу. Тестувальник використовує статут тесту, що містить цілі тесту, щоб керувати тестуванням. Після тестової сесії зазвичай слідує дебрифінг, який передбачає обговорення між тестувальником та зацікавленими сторонами, зацікавленими в результатах тестової сесії. У цьому підході цілі тестування можна розглядати як умови тестування високого рівня. Елементи покриття визначаються та відпрацьовуються під час тестової сесії. Тестувальник може використовувати аркуші тестового сеансу, щоб задокументувати виконані кроки та зроблені відкриття.
Дослідницьке тестування є корисним, коли специфікацій мало або вони неадекватні, або коли тестування потребує значного часу. Дослідницьке тестування також корисно як доповнення до інших більш формальних методів тестування. Дослідницьке тестування буде більш ефективним, якщо тестувальник має досвід, володіє предметними знаннями та високим ступенем основних навичок, таких як аналітичні здібності, допитливість і креативність. Дослідницьке тестування може включати використання інших методів тестування (наприклад, поділу на класи еквівалентності).
Тестування на основі контрольного списку (версія 3.1)
У тестуванні на основі контрольного списку тестувальники розробляють, реалізують і виконують тести, щоб охопити умови тестування, які містяться в контрольному списку. У рамках аналізу тестувальники створюють новий контрольний список або розширюють наявний контрольний список, але тестувальники також можуть використовувати наявний контрольний список без змін. Такі контрольні списки можна створити на основі досвіду, знань про те, що важливо для користувача, або розуміння того, чому та як програмне забезпечення дає збій.
Контрольні списки можна створювати для підтримки різних типів тестування, включаючи функціональне та нефункціональне тестування. За відсутності детальних тестових кейсів тестування на основі контрольного списку може надати вказівки та певну послідовність. Оскільки це списки високого рівня, у фактичному тестуванні, ймовірно, виникне певна мінливість, що призведе до потенційно більшого покриття, але меншої повторюваності.
Тестування на основі контрольного списку (версія 4.0)
У тестуванні на основі контрольного списку тестувальник розробляє, реалізує та виконує тести, щоб охопити умови тестування з контрольного списку. Контрольні списки можна створювати на основі досвіду, знань про те, що важливо для користувача, або розуміння того, чому та як програмне забезпечення дає збій. Контрольні списки не повинні містити пунктів, які можна перевірити автоматично, пунктів, які краще підходять як критерії входу/виходу, або пунктів, які є надто загальними (Brykczynski 1999).
Пункти контрольного списку часто формулюють у формі запитання. Повинна бути можливість перевірити кожен елемент окремо та безпосередньо. Ці елементи можуть стосуватися вимог, властивостей графічного інтерфейсу, характеристик якості або інших форм умов тестування. Контрольні списки можуть бути створені для підтримки різних типів тестів, включаючи функціональне та нефункціональне тестування.
Деякі записи контрольного списку з часом можуть поступово ставати менш ефективними, оскільки розробники навчаться уникати тих самих помилок. Також може знадобитися додати нові записи, щоб відобразити нещодавно виявлені дефекти високої серйозності. Тому контрольні списки слід регулярно оновлювати на основі аналізу дефектів. Однак слід бути обережним, щоб контрольний список не став занадто довгим (Gawande 2009).
За відсутності детальних тестових кейсів тестування на основі контрольного списку може надати вказівки та певний ступінь узгодженості для тестування. Якщо контрольні списки є високорівневими, певна мінливість у фактичному тестуванні, ймовірно, виникне, що призведе до потенційно більшого покриття, але меншої повторюваності.
ISTQB Certified Tester Foundation Level. Курс для початківців. Секція 4.4.
В цьому відео починаємо працювати з секцією 4.4. 00:00:37 Experience-based Test Techniques 00:03:14 Error Guessing 00:10:34 Exploratory Testing 00:21:25 Checklist-based Testing
Тестування білої скриньки базується на внутрішній структурі об’єкта тестування. Методи тестування білої скриньки можна використовувати на всіх рівнях тестування, але дві методики, пов’язані з кодом, розглянуті в цьому сілабусі, найчастіше використовуються на рівні тестування компонентів. Існують більш просунуті методи, які використовуються в деяких критично важливих для безпеки, критично важливих середовищах або середовищах із високим рівнем цілісності для досягнення більш повного покриття, але вони не рзглядаються.
Техніки тестування білої скриньки (версія 4.0)
Через їхню популярність і простоту цей розділ зосереджується на двох методах тестування білої скриньки, пов’язаних із кодом:
Перевірка операторів (тверджень, заяв)
Тестування гілок
Існують більш суворі методи, які використовуються в деяких критично важливих для безпеки, критично важливих середовищах або середовищах з високою цілісністю для досягнення більш повного покриття коду. Існують також методи тестування білої скриньки, які використовуються на вищих рівнях тестування (наприклад, тестування API) або використовують покриття, не пов’язане з кодом (наприклад, покриття нейронів у тестуванні нейронної мережі). Ці техніки не обговорюються в цьому сілабусі.
Тестування операторів і покриття (версія 3.1)
Тестування операторів перевіряє потенційні виконувані оператори в коді. Покриття вимірюється як кількість операторів, виконаних тестами, поділена на загальну кількість виконуваних операторів у тестовому об’єкті, зазвичай виражається у відсотках.
Тестування операторів і покриття (версія 4.0)
У тестуванні операторів елементи покриття є виконуваними операторами. Мета полягає в тому, щоб розробити тестові кейси, які виконують оператори в коді, доки не буде досягнуто прийнятний рівень покриття. Покриття вимірюється як кількість операторів, які виконуються тестовими кейсами, поділена на загальну кількість виконуваних операторів у коді та виражається у відсотках.
Коли досягнуто 100% охоплення операторів, це гарантує, що всі виконувані оператори в коді були виконані принаймні один раз. Зокрема, це означає, що кожен оператор з дефектом буде виконано, що може спричинити збій, що демонструє наявність дефекту. Однак виконання оператора з тестовим випадком не виявить дефекти у всіх випадках. Наприклад, він може не виявити дефекти, які залежать від даних (наприклад, ділення на нуль, яке не виконується лише тоді, коли знаменник встановлений на нуль). Крім того, 100% охоплення операторів не гарантує, що вся логіка прийняття рішень була протестована, оскільки, наприклад, вона може не виконувати всі гілки в коді.
Тестування рішень і покриття (версія 3.1)
Тестування рішень перевіряє рішення в коді та перевіряє код, який виконується на основі результатів рішень. Для цього тестові кейси слідують за потоками керування, які починаються з точки прийняття рішення (наприклад, для оператора IF, один для істинного результату та один для хибного результату; для оператора CASE тестові випадки будуть потрібні для всіх можливі результатів, включаючи результат за замовчуванням).
Покриття вимірюється як кількість результатів рішень, виконаних тестами, поділена на загальну кількість результатів рішень в об’єкті тестування, зазвичай виражається у відсотках.
Тестування гілок і покриття (версія 4.0)
Розгалуження — це передача керування між двома вузлами в графі потоку керування, який показує можливі послідовності, у яких оператори вихідного коду виконуються в тестовому об’єкті. Кожна передача контролю може бути або безумовною (тобто прямолінійним кодом), або умовною (тобто результатом рішення).
У тестуванні розгалужень елементами покриття є розгалуження, а метою є розробка тестових випадків для виконання розгалужень у коді, доки не буде досягнуто прийнятний рівень покриття. Покриття вимірюється як кількість розгалужень, які здійснюються тестовими випадками, поділена на загальну кількість розгалужень і виражається у відсотках.
Коли досягається 100% покриття розгалужень, усі розгалуження в коді, безумовні та умовні, перевіряються тестовими випадками. Умовні розгалуження зазвичай відповідають істинному чи хибному результату рішення «якщо…тоді», результату оператора switch/case або рішення вийти чи продовжити цикл. Однак виконання гілки за допомогою тестового кейсу не виявить дефекти у всіх випадках. Наприклад, він може не виявити дефекти, які потребують виконання певного шляху в коді.
Покриття гілок включає покриття операторів. Це означає, що будь-який набір тестів, який досягає 100% покриття гілок, також досягає 100% покриття операторів (але не навпаки).
Засноване на структурі або білої скриньки (Structure-based or White-box)
Тестування на основі структури або білої скриньки базується на визначеній структурі програмного забезпечення або системи, як показано в наведених нижче прикладах:
Тестування операторів (заяв) і покриття
Тестування рішень і покриття
Інші методи на основі структури: покриття умов
Рівні
Рівень компонента: структура програмного компонента, тобто оператори, рішення, гілки або навіть окремі шляхи.
Рівень інтеграції: структура може бути вільною від виклику (схема, на якій модулі викликають інші модулі).
Системний рівень: структура може бути структурою меню, бізнес-процесом або структурою веб-сторінки.
Покриття операторів вимірюється як кількість операторів, виконаних тестами, поділена на загальну кількість виконуваних операторів у тестовому об’єкті, зазвичай виражається у відсотках.
Тестування рішень створює тестові випадки для виконання конкретних результатів рішень, як правило, щоб збільшити охоплення рішень.
Покриття рішень вимірюється як кількість результатів рішень, виконаних тестами, поділена на загальну кількість результатів рішень в об’єкті тестування, зазвичай виражається у відсотках.
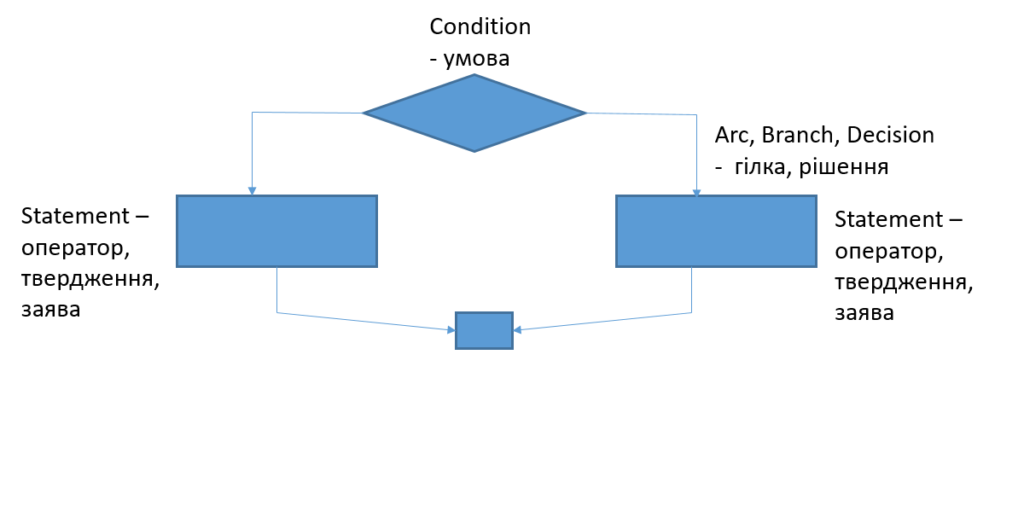
Для кращої візуалізації і знаходження правильних відповідей у тестах варто будувати схеми коду. Для цього можна використовувати наступні позначення.
Цикломатична складність
Цикломатична складність Маккейба — це максимальна кількість лінійних незалежних шляхів у програмі.
Формула цикломатичної складності:
M = L – N + 2*P
Де
L – кількість ребер/ланок у графі
N – кількість вузлів у графі
P – кількість з’єднаних компонентів
Приклад:
Потік керування показує сім вузлів (фігур) і вісім ребер (лінії), таким чином, використовуючи формальну формулу, цикломатична складність становить 8-7 + 2*1=3. У цьому випадку немає виклику графа або підпрограми.
Приклади тестових питань
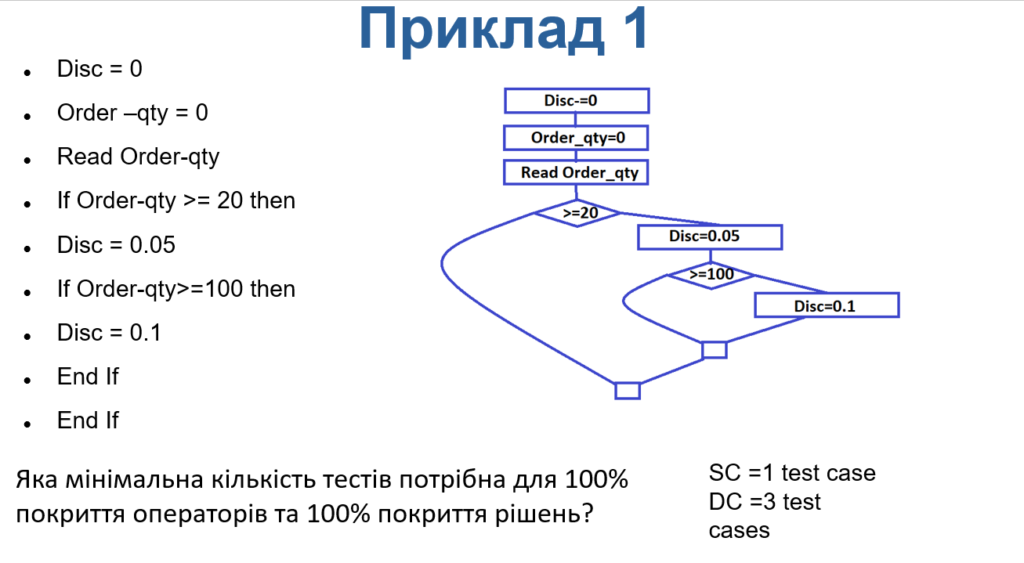
Яка мінімальна кількість тестів потрібна для 100% покриття операторів та 100% покриття рішень?
Disc = 0
Order –qty = 0
Read Order-qty
If Order-qty >= 20 then
Disc = 0.05
If Order-qty>=100 then
Disc = 0.1
End If
End If
З наведеної схеми видно, що для покриття стейтментів знадобиться один тест кейс, а для покриття рішень – 3 тест кейса.
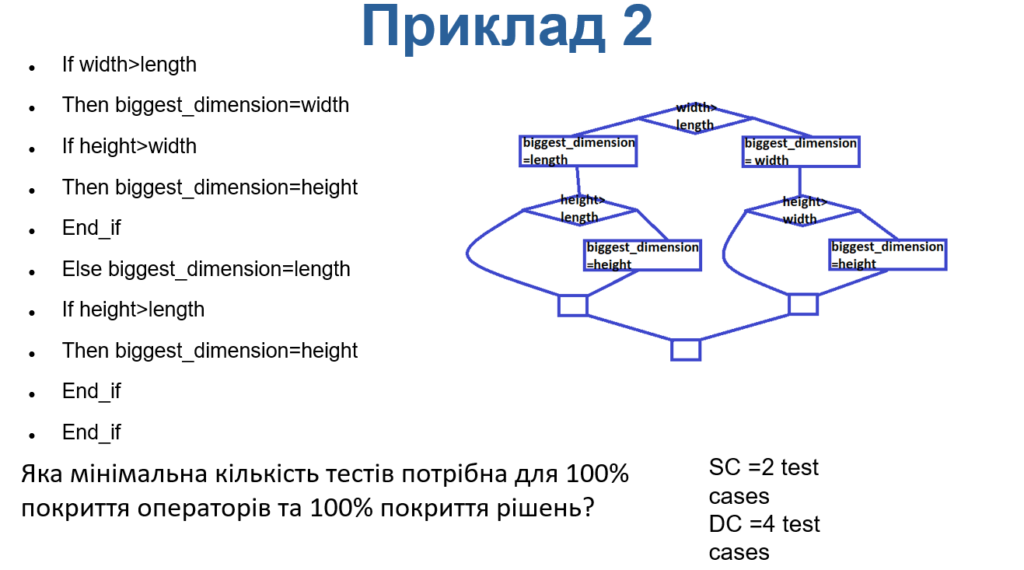
Яка мінімальна кількість тестів потрібна для 100% покриття операторів та 100% покриття рішень?
If width>length
Then biggest_dimension=width
If height>width
Then biggest_dimension=height
End_if
Else biggest_dimension=length
If height>length
Then biggest_dimension=height
End_if
End_if
З наведеної схеми видно, що для покриття стейтментів знадобиться 2 тест кейса, а для покриття рішень – 4 тест кейса.
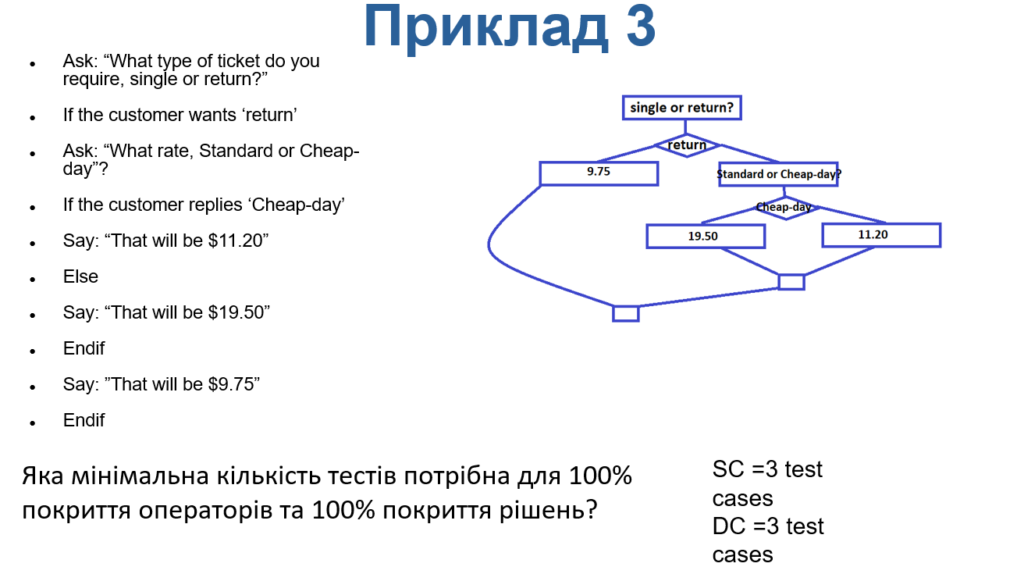
Яка мінімальна кількість тестів потрібна для 100% покриття операторів та 100% покриття рішень?
Ask: “What type of ticket do you require, single or return?”
If the customer wants ‘return’
Ask: “What rate, Standard or Cheap-day”?
If the customer replies ‘Cheap-day’
Say: “That will be $11.20”
Else
Say: “That will be $19.50”
Endif
Say: ”That will be $9.75”
Endif
З наведеної схеми видно, що для покриття стейтментів знадобиться 3 тест кейса, а для покриття рішень також – 3 тест кейса. Цей приклад демонструє, що в ряді ситуацій кількість тест кейсів для 100% покриття рішень може збігатися з кількістю тест кейсів для покриття операторів.
Значення тестування операторів і рішень (версія 3.1)
Коли досягнуто 100% покриття операторів, це гарантує, що всі виконувані оператори в коді були протестовані принаймні один раз, але це не гарантує, що перевірено всю логіку прийняття рішень. З двох методів білого ящика, які обговорюються в цьому навчальному плані, тестування тверджень може забезпечити менше охоплення, ніж тестування рішень.
Коли досягнуто 100% покриття рішення, воно виконує всі результати рішення, що включає перевірку істинного результату, а також хибного результату, навіть якщо немає явного хибного оператора (наприклад, у випадку оператора IF без else в коді)). Покриття операторів допомагає знайти дефекти в коді, які не перевірялися іншими тестами. Покриття рішень допомагає знаходити дефекти в коді, де інші тести не приймають ні правдивих, ні хибних результатів.
Досягнення 100% покриття рішень гарантує 100% покриття операторів (але не навпаки).
Значення тестування білої скриньки (версія 4.0)
Фундаментальна сильна сторона всіх методів «білої скриньки» полягає в тому, що під час тестування враховується вся реалізація програмного забезпечення, що полегшує виявлення дефектів, навіть якщо специфікація програмного забезпечення розпливчаста, застаріла або неповна. Відповідна слабкість полягає в тому, що якщо програмне забезпечення не реалізує одну або більше вимог, тестування білого ящика може не виявити отримані дефекти упущення (Watson 1996).
Методи білої скриньки можна використовувати в статичному тестуванні (наприклад, під час пробних прогонів коду). Вони добре підходять для перегляду коду, який ще не готовий до виконання (Hetzel 1988), а також псевдокоду та іншої логіки високого рівня або низхідної логіки, яку можна моделювати за допомогою графа потоку керування.
Виконання лише тестування чорної скриньки не забезпечує вимірювання фактичного покриття коду. Показники покриття білої скриньки забезпечують об’єктивне вимірювання покриття та надають необхідну інформацію, щоб дозволити створити додаткові тести для збільшення цього покриття та згодом підвищити довіру до коду.
ISTQB Certified Tester Foundation Level. Курс для початківців. Секція 4.3.
В цьому відео починаємо працювати з секцією 4.3. 00:01:16 White-box Test Techniques 00:06:21 Statement Testing and Coverage 00:12:47 Decision Testing and Coverage 00:23:07 Structure-based or White-box 00:20:21 Cyclomatic complexity 00:37:56 Приклади тестів 00:59:14 The Value of Statement and Decision Testing
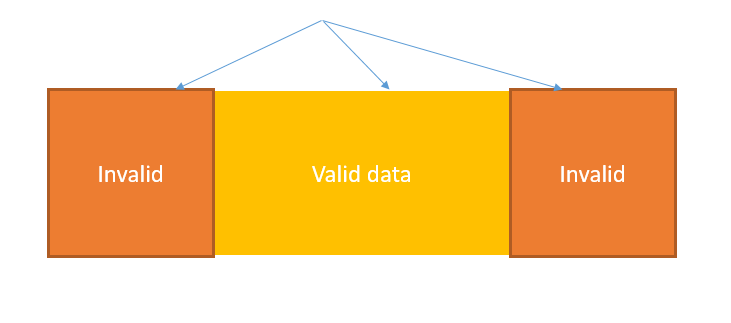
Поділ еквівалентності ділить дані на розділи (також відомі як класи еквівалентності) таким чином, щоб усі члени певного розділу оброблялися однаково. Існують розділи еквівалентності як для дійсних, так і для недійсних значень.
Дійсні значення – це значення, які повинні бути прийняті компонентом або системою. Розділ еквівалентності, що містить дійсні значення, називається «дійсним розділом еквівалентності».
Недійсні значення – це значення, які повинні бути відхилені компонентом або системою. Розділ еквівалентності, що містить недійсні значення, називається «недійсним розділом еквівалентності».
Розділи можна ідентифікувати для будь-якого елемента даних, пов’язаного з тестовим об’єктом, включаючи входи, виходи, внутрішні значення, значення, пов’язані з часом (наприклад, до або після події), а також для параметрів інтерфейсу (наприклад, інтегровані компоненти, що тестуються під час інтеграційного тестування).
Будь-який розділ можна розділити на підрозділи, якщо потрібно. Кожне значення має належати одному й лише одному розділу еквівалентності.
Якщо в тестових кейсах використовуються недійсні розділи еквівалентності, їх слід тестувати окремо, тобто не поєднувати з іншими недійсними розділами еквівалентності, щоб гарантувати, що помилки не маскуються. Збої можуть бути замасковані, коли кілька збоїв відбуваються одночасно, але лише один видимий, через що інші збої не виявляються.
Щоб досягти 100% покриття за допомогою цієї техніки, тестові кейси повинні охоплювати всі визначені розділи (включаючи недійсні розділи), використовуючи принаймні одне значення з кожного розділу. Покриття вимірюється як кількість розділів еквівалентності, перевірених принаймні одним значенням, поділена на загальну кількість визначених розділів еквівалентності, зазвичай виражену у відсотках. Поділ еквівалентності застосовується на всіх рівнях тестування.
Поділ на класи еквівалентності (версія 4.0)
Поділ еквівалентності ділить дані на розділи (відомі як розділи еквівалентності) на основі очікування, що всі елементи даного розділу будуть оброблятися об’єктом тестування однаково. Теорія, яка лежить в основі цієї техніки, полягає в тому, що якщо тестовий кейс, який перевіряє одне значення з розділу еквівалентності, виявляє дефект, цей дефект також має бути виявлений тестовими прикладами, які перевіряють будь-яке інше значення з того самого розділу. Тому достатньо одного тесту для кожного розділу.
Розділи еквівалентності можуть бути ідентифіковані для будь-якого елемента даних, пов’язаного з об’єктом тестування, включаючи входи, виходи, елементи конфігурації, внутрішні значення, значення, пов’язані з часом, і параметри інтерфейсу. Розділи можуть бути неперервними або дискретними, упорядкованими або невпорядкованими. Розділи не повинні перекриватися і повинні бути непорожніми наборами.
Для простих тестових об’єктів поділ на класи еквівалентності може бути легким, але на практиці розуміння того, як тестовий об’єкт оброблятиме різні значення, часто є складним. Тому до меж класів слід підходити обережно.
Розділ, що містить дійсні значення, називається дійсним розділом. Розділ, що містить недійсні значення, називається недійсним розділом. Визначення дійсних і недійсних значень можуть відрізнятися в різних командах і організаціях. Наприклад, дійсні значення можуть бути інтерпретовані як ті, які повинні бути оброблені тестовим об’єктом, або як ті, для яких специфікація визначає їх обробку. Недійсні значення можуть бути інтерпретовані як ті, які повинні бути проігноровані або відхилені тестовим об’єктом, або як такі, для яких у специфікації тестового об’єкта не визначена обробка.
У поділі на класи еквівалентності елементами покриття є розділи еквівалентності. Щоб досягти 100% охоплення за допомогою цієї методики, тестові випадки повинні перевіряти всі визначені розділи (включаючи недійсні розділи), покриваючи кожен розділ принаймні один раз. Покриття вимірюється як кількість розділів, виконаних принаймні одним тестовим випадком, поділена на загальну кількість ідентифікованих розділів і виражається у відсотках.
Багато тестових об’єктів включають кілька наборів розділів (наприклад, тестові об’єкти з більш ніж одним вхідним параметром), що означає, що тестовий приклад охоплюватиме розділи з різних наборів розділів. Найпростіший критерій покриття у випадку кількох наборів розділів називається покриттям кожного вибору (Ammann 2016). Кожне покриття вибору вимагає тестових кейсів для виконання кожного розділу з кожного набору розділів принаймні один раз. Кожне покриття вибору не враховує комбінації на межах класів.
Ілюстрація до поділу на класи еквівалентності
Отже спрощено, поділ на класи еквівалентності (Equivalence Partitioning) – це техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені для виконання елементів із розділів еквівалентності. У принципі, тестові випадки розроблені для покриття кожного розділу принаймні один раз.
Приклад тестового питання:
В цьому прикладі умовно можна виділити 5 класів еквівалентності і лише відповідь B) покриває всі визначені класи.
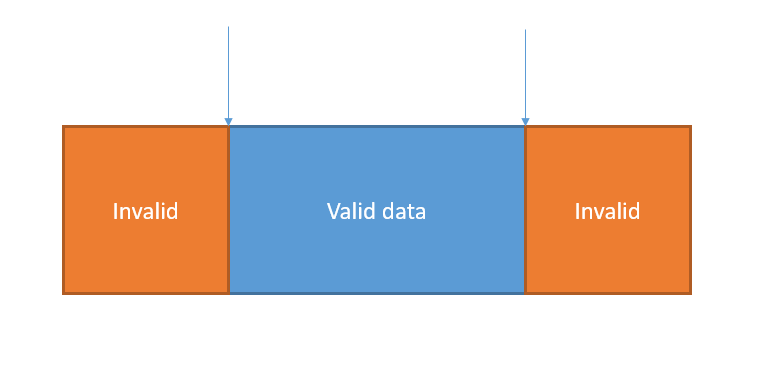
Аналіз граничних значень (версія 3.1)
Аналіз граничних значень (BVA) є розширенням поділу на класи еквівалентності, але його можна використовувати лише тоді, коли розділ впорядкований і складається з числових або послідовних даних. Мінімальне та максимальне значення (або перше та останнє значення) розділу є його граничними значеннями.
Наприклад, припустімо, що поле введення приймає одне ціле значення як вхідні дані, використовуючи клавіатуру для обмеження введення таким чином, щоб неціле число було неможливим. Допустимий діапазон – від 1 до 5 включно. Отже, є три розділи еквівалентності: недійсний (занадто низький); дійсний; недійсний (занадто високий). Для дійсного розділу еквівалентності граничними значеннями є 1 і 5. Для недійсного (занадто високого) розділу граничне значення дорівнює 6. Для недійсного (занадто низького) розділу існує лише одне граничне значення, 0, оскільки це розділ лише з одним членом.
У наведеному вище прикладі ми визначаємо два граничні значення на межу. Межа між недійсним (занадто низьким) і дійсним дає тестові значення 0 і 1. Межа між дійсним і недійсним (занадто високим) дає тестові значення 5 і 6. Деякі варіанти цього методу визначають три граничні значення на межу: значення перед, біля та безпосередньо за межею. У попередньому прикладі з використанням трьохточкових граничних значень нижні граничні випробувальні значення становлять 0, 1 і 2, а верхні граничні випробувальні значення – 4, 5 і 6.
Поведінка на межах розділів еквівалентності, швидше за все, буде неправильною, ніж поведінка всередині розділів. Важливо пам’ятати, що як визначені, так і впроваджені межі можуть бути зміщені вище або нижче запланованих положень, можуть бути взагалі не встановлені або можуть бути доповнені небажаними додатковими межами. Аналіз і тестування граничних значень виявлять майже всі такі дефекти, змушуючи програмне забезпечення показувати поведінку з розділу, відмінного від того, до якого має належати граничне значення.
Аналіз граничних значень можна застосовувати на всіх рівнях тестування. Ця техніка зазвичай використовується для перевірки вимог, які вимагають діапазону чисел (включаючи дати та час). Граничне покриття для розділу вимірюється як кількість протестованих граничних значень, поділена на загальну кількість визначених граничних тестових значень, зазвичай виражених у відсотках.
Аналіз граничних значень (версія 4.0)
Аналіз граничних значень (BVA) — це техніка, яка базується на вивченні меж розділів еквівалентності. Тому BVA можна використовувати тільки для ситуацій, коли можна визначити межі. Мінімальне і максимальне значення розділу є його граничними значеннями. У випадку BVA, якщо два елементи належать до одного розділу, усі елементи між ними також повинні належати до цього розділу.
BVA зосереджується на граничних значеннях розділів, тому що розробники частіше помиляються з цими граничними значеннями. Типові дефекти, виявлені BVA, знаходяться там, де встановлені межі неправильно розташовані вище або нижче їх запланованих положень або взагалі не встановлені.
Цей навчальний сілабус охоплює дві версії BVA: 2-значний і 3-значний BVA. Вони відрізняються за елементами охоплення на межі, які необхідно використовувати для досягнення 100% покриття.
У BVA з двома значеннями (Craig 2002, Myers 2011) для кожного граничного значення є два елементи покриття: це граничне значення та його найближчий сусід, що належить до сусіднього розділу. Щоб досягти 100% покриття за допомогою 2-значного BVA, тестові випадки повинні використовувати всі елементи покриття, тобто всі визначені граничні значення.
Покриття вимірюється як кількість перевірених граничних значень, поділена на загальну кількість визначених граничних значень і виражається у відсотках.
У BVA з 3 значеннями (Koomen 2006, O’Regan 2019) для кожного граничного значення є три елементи покриття: це граничне значення та обидва його сусідні. Тому в 3-значному BVA деякі з елементів покриття можуть не бути граничними значеннями. Щоб досягти 100% охоплення за допомогою 3-значного BVA, тестові випадки повинні виконувати всі елементи охоплення, тобто визначені граничні значення та їхні сусіди. Покриття вимірюється як кількість використаних граничних значень та їхніх сусідів, поділена на загальну кількість визначених граничних значень та їхніх сусідів, і виражається у відсотках.
3-значний BVA є більш суворим, ніж 2-значний BVA, оскільки він може виявити дефекти, пропущені 2-значним BVA. Наприклад, якщо рішення «якщо (x ≤ 10) …» неправильно реалізовано як «якщо (x = 10) …», жодні тестові дані, отримані з 2-значного BVA (x = 10, x = 11), не можуть виявити дефект. Однак x = 9, отримане з 3-значного BVA, ймовірно, виявить це.
Ілюстрація аналізу граничних значень
Аналіз граничних значень (Boundary value analysis): Техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені на основі граничних значень.
Приклад тестового запитання:
В цьому прикладі правильною відповіддю є 33501, оскільки 4000+1500+28000 дає 33501. Отже, межі це 4000, 5500 і 33500. З наявних варіантів 33501 підпадає під техніку аналізу граничних значень.
Тестування таблиці рішень (версія 3.1)
Таблиці рішень є хорошим способом запису складних бізнес-правил, які система повинна реалізувати. Створюючи таблиці рішень, тестувальник визначає умови (часто входи) і кінцеві дії (часто виходи) системи. Вони утворюють рядки таблиці, зазвичай з умовами вгорі та діями внизу. Кожен стовпець відповідає правилу прийняття рішень, яке визначає унікальну комбінацію умов, що призводить до виконання дій, пов’язаних із цим правилом. Значення умов і дій зазвичай відображаються як логічні значення (істина чи хибність) або дискретні значення (наприклад, червоний, зелений, синій), але також можуть бути числами чи діапазонами чисел. Ці різні типи умов і дій можна знайти разом в одній таблиці.
Загальні позначення в таблицях рішень для умов такі:
Y означає, що умова виконується (також може відображатися як T або 1)
N означає, що умова хибна (також може відображатися як F або 0)
— означає, що значення умови не має значення (також може відображатися як N/A) Для дій:
X означає, що дія має відбутися (також може відображатися як Y, T або 1)
Порожнє означає, що дія не повинна відбуватися (також може відображатися як – або N, або F, або 0)
Повна таблиця рішень містить достатню кількість стовпців (тестових кейсів), щоб охопити кожну комбінацію умов. Видаляючи стовпці, які не впливають на результат, можна значно зменшити кількість тестів. Наприклад, видаливши неможливі комбінації умов. Щоб отримати додаткові відомості про те, як згорнути таблиці рішень.
Загальний мінімальний стандарт охоплення для тестування таблиці рішень полягає в наявності принаймні одного тестового випадку на правило прийняття рішень у таблиці. Зазвичай це передбачає охоплення всіх комбінацій умов. Покриття вимірюється як кількість правил прийняття рішень, перевірених принаймні одним тестовим випадком, поділена на загальну кількість правил прийняття рішень, зазвичай виражених у відсотках.
Сильна сторона тестування таблиці рішень полягає в тому, що воно допомагає визначити всі важливі комбінації умов, деякі з яких інакше можна було б проігнорувати. Це також допомагає знайти прогалини у вимогах. Його можна застосовувати до всіх ситуацій, у яких поведінка програмного забезпечення залежить від комбінації умов, на будь-якому рівні тестування.
Тестування таблиці рішень (версія 4.0)
Таблиці рішень використовуються для перевірки виконання системних вимог, які визначають, як різні комбінації умов призводять до різних результатів. Таблиці рішень — це ефективний спосіб запису складної логіки, наприклад бізнес-правил.
При створенні таблиць рішень визначаються умови та результуючі дії системи. Вони утворюють рядки таблиці. Кожен стовпець відповідає правилу прийняття рішень, яке визначає унікальну комбінацію умов разом із відповідними діями. У таблицях рішень з обмеженим входом усі значення умов і дій (за винятком нерелевантних або нездійсненних; див. нижче) відображаються як логічні значення (істина або хибність). Крім того, у таблицях рішень із розширеним записом деякі або всі умови та дії також можуть мати кілька значень (наприклад, діапазони чисел, розділи еквівалентності, дискретні значення).
Умови позначаються наступним чином: «T» (true) означає, що умова виконана. «F» (false) означає, що умова не виконується. «–» означає, що значення умови не має значення для результату дії. «N/A» означає, що умова є нездійсненною для даного правила. Для дій: «X» означає, що дія має відбутися. Відсутнє значення означає, що дія не повинна відбуватися. Також можуть використовуватися інші позначення.
Повна таблиця рішень має достатню кількість стовпців, щоб охопити кожну комбінацію умов. Таблицю можна спростити, видаливши стовпці, що містять нездійсненні комбінації умов. Таблицю також можна згорнути, об’єднавши стовпці, у яких деякі умови не впливають на результат, в один стовпець. Алгоритми мінімізації таблиці рішень виходять за межі цієї навчальної програми.
У тестуванні таблиці рішень елементами покриття є стовпці, що містять можливі комбінації умов. Щоб досягти 100% охоплення за допомогою цієї методики, тестові випадки повинні використовувати всі ці стовпці. Покриття вимірюється як кількість використаних колонок, поділена на загальну кількість можливих колонок, і виражається у відсотках.
Сильна сторона тестування таблиці рішень полягає в тому, що воно забезпечує систематичний підхід до визначення всіх комбінацій умов, деякі з яких інакше можна було б проігнорувати. Це також допомагає знайти будь-які прогалини або протиріччя у вимогах. Якщо існує багато умов, виконання всіх правил прийняття рішень може зайняти багато часу, оскільки кількість правил експоненціально зростає разом із кількістю умов. У такому випадку, щоб зменшити кількість правил, які необхідно виконувати, можна використовувати мінімізовану таблицю рішень або підхід, заснований на оцінці ризику.
Ілюстрація тестування таблиці рішень
Тестування таблиці рішень (Decision Table Testing): Техніка розробки тестів чорної скриньки, у якій тестові кейси розроблені для виконання комбінацій вхідних даних, показаних у таблиці рішень.
Приклад
Правила роботи:
Кредит не надається безробітним
Кредит надається особам, які мають постійну легальну роботу без обмежень
Вікові правила:
Особам до 18 років кредит не надається
Цільовою групою для отримання кредиту є люди 18-40 років
Для осіб старше 40 років не надається
Правила доходу:
Кредит не надається людям з доходом менше 1000 доларів США на місяць
Кредит надається особам з доходом 1000-5000 USD/місяць, сума кредиту < 2000 USD
Кредит надається людям з доходом понад 5000 доларів США на місяць, сума кредиту > 2000 доларів США
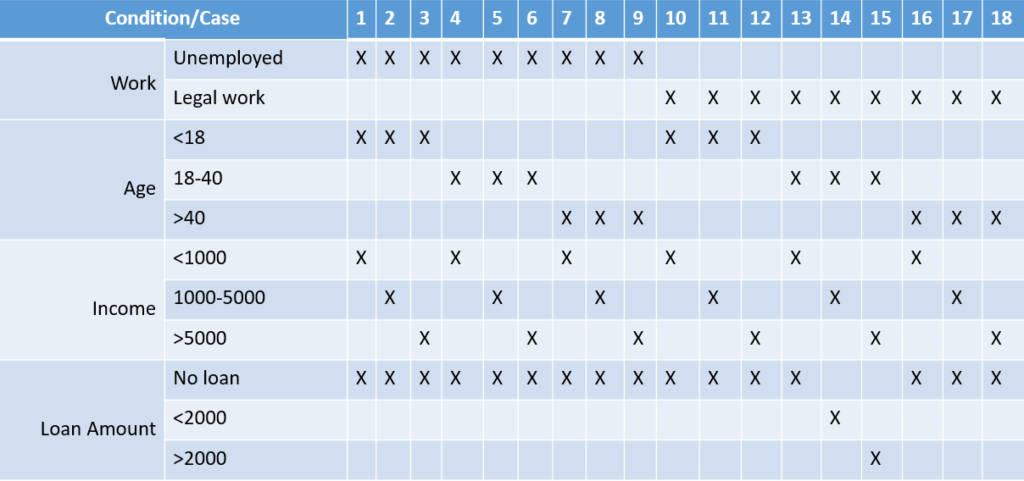
Результат поєднання правил видачі кредитів можна представити наступною таблицею:
Як приклад можуть попросити визначити очікувані результати для наступних тест кейсів.
Test cases:
Student, unemployed, 17 years old, income is 80 USD/month
Post graduate, unemployed, 24 years old, no income
Retired, unemployed, 62 years old, income is 200 USD/month
Manager, legally employed, 50 years old, income 1500 USD/month
Tester, legally employed, 40 years old, income 2000 USD/month
З наявних прикладів, кредит повинен бути наданий тільки по 5 тест кейсу. В усіх інших випадках у видачі кредиту повинно бути відмовлено.
Тестування переходу стану (верся 3.1)
Компоненти або системи можуть по-різному реагувати на подію залежно від поточних умов або попередньої історії (наприклад, подій, які відбулися після ініціалізації системи). Попередню історію можна підсумувати за допомогою поняття станів. Діаграма переходу станів показує можливі стани програмного забезпечення, а також те, як програмне забезпечення входить, виходить і переходить між станами. Перехід ініціюється подією (наприклад, введення користувачем значення в поле). Результатом події є перехід. Та сама подія може призвести до двох або більше різних переходів з одного стану. Зміна стану може призвести до того, що програмне забезпечення виконає певну дію (наприклад, виведе обчислення або повідомлення про помилку).
Таблиця переходів станів показує всі дійсні переходи та потенційно недійсні переходи між станами, а також події та результуючі дії для дійсних переходів. Діаграми переходів станів зазвичай показують лише дійсні переходи та виключають недійсні переходи.
Тести можуть бути розроблені для охоплення типової послідовності станів, для виконання всіх станів, для виконання кожного переходу, для виконання конкретних послідовностей переходів або для перевірки недійсних переходів.
Тестування переходу стану використовується для додатків на основі меню та широко використовується в галузі вбудованого програмного забезпечення. Техніка також підходить для моделювання бізнес-сценарію з певними станами або для тестування екранної навігації. Концепція стану є абстрактною – вона може представляти кілька рядків коду або цілий бізнес-процес.
Покриття зазвичай вимірюється як кількість ідентифікованих станів або переходів, що перевіряються, поділена на загальну кількість ідентифікованих станів або переходів у тестовому об’єкті, зазвичай виражену у відсотках. Для отримання додаткової інформації про критерії охоплення для тестування на перехід до стану.
Тестування переходу стану (версія 4.0)
Діаграма переходів станів моделює поведінку системи, показуючи її можливі стани та дійсні переходи станів. Перехід ініціюється подією, яка може бути додатково кваліфікована умовою захисту. Передбачається, що переходи відбуваються миттєво і іноді можуть призвести до виконання дій програмним забезпеченням. Загальний синтаксис маркування переходів такий: «подія [охоронна умова] / дія». Охоронні умови та дії можна пропустити, якщо вони не існують або не мають значення для тестувальника.
Таблиця станів — це модель, еквівалентна діаграмі переходів станів. Його рядки представляють стани, а стовпці представляють події (разом із умовами захисту, якщо вони існують). Записи таблиці (комірки) представляють переходи та містять цільовий стан, а також результуючі дії, якщо вони визначені. На відміну від діаграми переходів станів, таблиця станів явно показує недійсні переходи, які представлені порожніми комірками.
Тестовий приклад, заснований на діаграмі переходів станів або таблиці станів, зазвичай представляється як послідовність подій, що призводить до послідовності змін стану (і дій, якщо необхідно). Один тестовий приклад може охоплювати і зазвичай буде охоплювати кілька переходів між станами.
Існує багато критеріїв охоплення для тестування переходу на державний рівень. У цій програмі розглядаються три з них.
У всіх зонах покриття пунктами покриття є стани. Щоб досягти 100% покриття всіх станів, тестові кейси повинні гарантувати відвідування всіх станів. Покриття вимірюється як кількість відвіданих станів, поділена на загальну кількість станів і виражається у відсотках.
У покритті дійсних переходів елементи покриття є одними дійсними переходами. Щоб досягти 100% дійсного покриття переходів, тестові приклади повинні виконувати всі дійсні переходи. Покриття вимірюється як кількість здійснених дійсних переходів, поділена на загальну кількість дійсних переходів, і виражається у відсотках.
У покритті всіх переходів елементами покриття є всі переходи, показані в таблиці станів. Щоб досягти 100% покриття всіх переходів, тестові кейси повинні виконувати всі дійсні переходи та намагатися виконати недійсні переходи. Тестування лише одного недійсного переходу в одному тестовому кейсі допомагає уникнути маскування помилки, тобто ситуації, коли один дефект перешкоджає виявленню іншого. Покриття вимірюється як кількість дійсних і недійсних переходів, здійснених або спробованих охопити виконаними тестами, поділена на загальну кількість дійсних і недійсних переходів і виражається у відсотках.
Охоплення всіх станів слабше, ніж охоплення дійсних переходів, оскільки його зазвичай можна досягти без виконання всіх переходів. Дійсне покриття переходів є найбільш широко використовуваним критерієм покриття.
Досягнення повного дійсного покриття переходів гарантує повне покриття всіх станів. Досягнення повного охоплення всіх переходів гарантує як повне охоплення всіх станів, так і повне охоплення дійсних переходів і має бути мінімальною вимогою для критично важливого для безпеки програмного забезпечення.
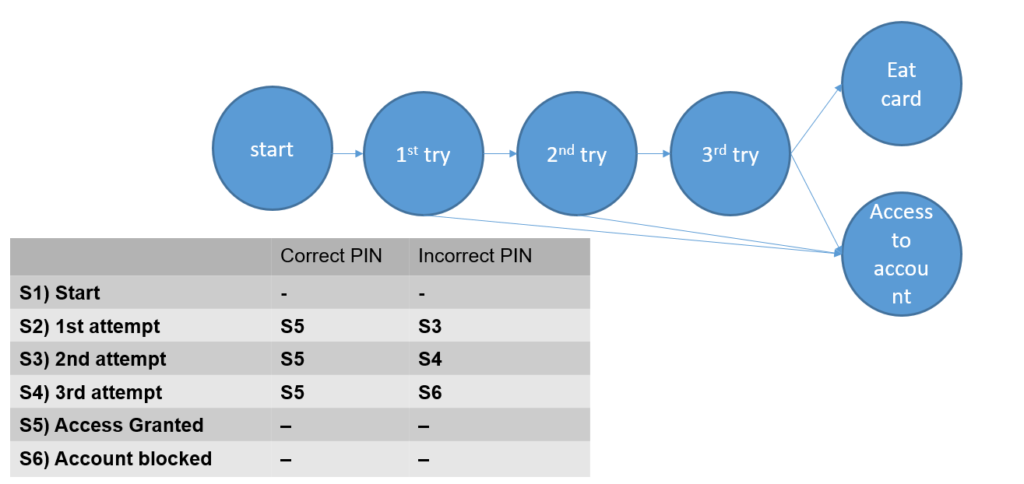
Ілюстрація тестування переходу стану
Популярний приклад для ілюстрації – переходи станів при спробі отримати доступ до свого рахунку в банкоматі. Три спроби для введення pin-коду, у разі введення неправильного коду тричі банкомат “з’їдає” картку. В цьому прикладі добре видно, що для тестування всіх станів достатньо буде двох тест кейсів.
Тестування варіантів використання (версія 3.1)
Тести можуть бути отримані з варіантів використання, які є особливим способом проєктування взаємодії з елементами програмного забезпечення. Вони містять вимоги до програмних функцій. Варіанти використання пов’язані з виконавцями (користувачами, зовнішнім апаратним забезпеченням або іншими компонентами чи системами) і суб’єктами (компонентом або системою, до якої застосовано варіант використання).
Кожен варіант використання визначає певну поведінку, яку суб’єкт може виконувати у співпраці з одним або кількома виконавцями (UML 2.5.1 2017). Випадок використання може бути описаний взаємодіями та діями, а також передумовами, постумовами та природною мовою, де це доречно. Взаємодія між виконавцями та суб’єктом може призвести до змін стану суб’єкта. Взаємодії можуть бути представлені графічно за допомогою робочих процесів, діаграм діяльності або моделей бізнес-процесів.
Варіант використання може включати можливі варіації його базової поведінки, включаючи виняткову поведінку та обробку помилок (відповідь системи та відновлення після помилок програмування, програми та зв’язку, наприклад, що призводить до повідомлення про помилку). Тести призначені для перевірки визначеної поведінки (основної, виняткової або альтернативної та обробки помилок). Охоплення можна виміряти кількістю протестованих варіантів використання, розділеною на загальну кількість варіантів поведінки, зазвичай виражену у відсотках.
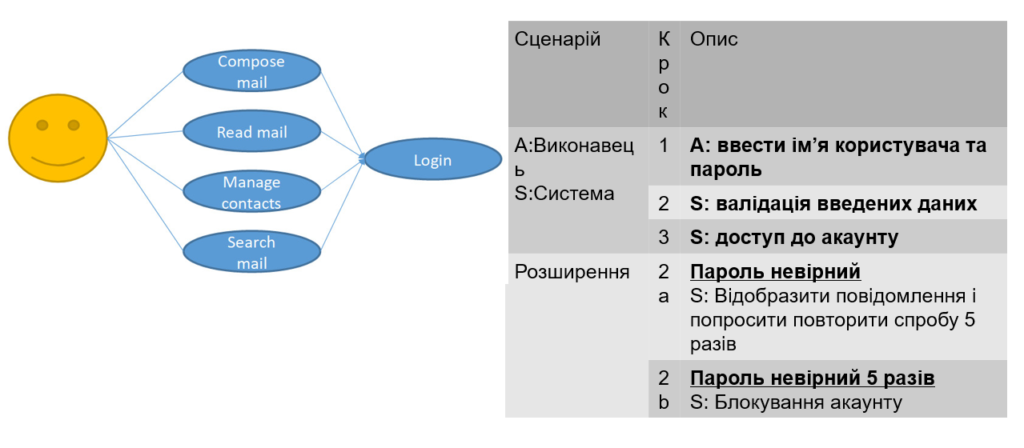
Теж популярний приклад ілюстрації тестування варіанітв використання (use case testing). Умовна система “Email” в якій користувач після логіну отримує доступ до своєї поштової скриньки і може писати листи, читати листи, керувати контактами, шукати листи. В таблиці представлені сценарії для логіну.
ISTQB Certified Tester Foundation Level. Курс для початківців. Секція 4.2.
В цьому відео починаємо працювати з секцією 4.2. 00:00:34 Equivalence Partitioning 00:18:26 Boundary Value Analysis 00:42:14 Приклади EP/BVA 00:58:37 Decision Table Testing 01:17:24 Приклад Decision Table Testing 01:30:31 State Transition Testing 01:57:23 Use case testing
Метою методів тестування є допомога у визначенні умов тестування, тестових кейсів і тестових даних.
Вибір методів тестування залежить від ряду факторів, зокрема:
Складність компонентів або системи
Регуляторні стандарти
Вимоги замовника або контракту
Рівні та типи ризиків
Наявна документація
Знань і навичок тестувальника
Доступних інструментів
Часу і бюджету
Моделі життєвого циклу розробки програмного забезпечення
Типів дефектів, які очікуються в компоненті чи системі
Деякі техніки більш застосовні до певних ситуацій і рівнів тестування; інші застосовні до всіх рівнів тестування. Створюючи тестові випадки, тестувальники зазвичай використовують комбінацію технік тестування, щоб досягти найкращих результатів тестування.
Використання методів тестування в аналізі тестів, розробці тестів і реалізації тестів може варіюватися від дуже неформального (відсутність документації) до дуже формального. Відповідний рівень формальності залежить від контексту тестування, включаючи зрілість процесів тестування та розробки, часові обмеження, вимоги щодо безпеки чи нормативні вимоги, знання та навички залучених людей і модель життєвого циклу розробки програмного забезпечення, яка використовується.
Методи тестування чорної скриньки (також називають поведінковими методами або техніками, заснованими на поведінці) ґрунтуються на аналізі відповідної тестової бази (наприклад, офіційних документів вимог, специфікацій, випадків використання, історій користувачів або бізнес-процесів). Ці методи застосовуються як для функціонального, так і для нефункціонального тестування. Методи тестування чорної скриньки зосереджуються на входах і виходах об’єкта тестування без посилання на його внутрішню структуру.
Методи тестування білої скриньки (також називаються структурними методами або методами на основі структури) базуються на аналізі архітектури, детального проєктування, внутрішньої структури або коду об’єкта тестування. На відміну від методів тестування чорного ящика, методи тестування білого ящика зосереджуються на структурі та обробці всередині тестового об’єкта.
Методи тестування на основі досвіду використовують досвід розробників, тестувальників і користувачів для розробки, реалізації та виконання тестів. Ці методи часто поєднуються з методами тестування чорної та білої скриньок.
Загальні характеристики методів тестування чорної скриньки включають наступне:
Умови тестування, тестові кейси та тестові дані отримані з тестової бази, яка може включати вимоги до програмного забезпечення, специфікації, варіанти використання та історії користувачів
Тестові приклади можуть бути використані для виявлення прогалин між вимогами та виконанням вимог, а також відхилень від вимог
Покриття вимірюється на основі елементів, протестованих у тестовій базі, і техніки, застосованої до тестової бази
Загальні характеристики методів тестування білого ящика включають:
Умови тестування, тестові випадки та тестові дані отримуються з тестової бази, яка може включати код, архітектуру програмного забезпечення, детальний дизайн або будь-яке інше джерело інформації щодо структури програмного забезпечення.
Покриття вимірюється на основі перевірених елементів у обраній структурі (наприклад, коду чи інтерфейсів) і методики, застосованої до тестової бази
Загальні характеристики методів тестування на основі досвіду включають:
Умови тестування, тестові кейси та тестові дані отримуються з тестової бази, яка може включати знання та досвід тестувальників, розробників, користувачів та інших зацікавлених сторін. Ці знання та досвід включають очікуване використання програмного забезпечення, його середовище, можливі дефекти та поширення цих дефектів
Міжнародний стандарт (ISO/IEC/IEEE 29119-4) містить описи методів тестування та відповідних показників покриття.
Категорії тестових технік (версія 4.0)
Методи тестування допомагають тестувальнику в аналізі тесту (що тестувати) і в дизайні тесту (як тестувати). Методи тестування допомагають систематично розробити відносно невеликий, але достатній набір тестів. Методи тестування також допомагають тестувальнику визначити умови тестування, ідентифікувати елементи покриття та ідентифікувати тестові дані під час аналізу та розробки тесту. Додаткову інформацію щодо методів тестування та відповідних заходів можна знайти в стандарті ISO/IEC/IEEE 29119-4, а також у (Beizer 1990, Craig 2002, Copeland 2004, Koomen 2006, Jorgensen 2014, Ammann 2016, Forgács 2019).
У цьому сілабусі методи тестування класифікуються як «чорної скриньки», «білої скриньки» і засновані на досвіді.
Методи тестування чорної скриньки (також відомі як методики на основі специфікацій) базуються на аналізі заданої поведінки об’єкта тестування без посилання на його внутрішню структуру. Таким чином, тестові випадки не залежать від того, як реалізовано програмне забезпечення. Отже, якщо реалізація змінюється, але необхідна поведінка залишається незмінною, тоді тестові випадки все ще корисні.
Методи тестування білої скриньки (також відомі як методи на основі структури) базуються на аналізі внутрішньої структури тестового об’єкта та обробки. Оскільки тестові кейси залежать від того, як розроблено програмне забезпечення, їх можна створити лише після розробки або впровадження тестового об’єкта.
Методи тестування, засновані на досвіді, ефективно використовують знання та досвід тестувальників для розробки та реалізації тестів. Ефективність цих методів значною мірою залежить від навичок тестувальника. Методи тестування, засновані на досвіді, можуть виявити дефекти, які можна пропустити за допомогою методів тестування чорної та білої скриньок. Таким чином, методи тестування, засновані на досвіді, доповнюють методи тестування чорної та білої скриньок.
ISTQB Certified Tester Foundation Level. Курс для початківців. Секція 4.1.
В цьому відео починаємо працювати з секцією 4.1. 00:00:54 Категорії тестових технік 00:09:25 Техніки чорної скриньки, білої скриньки, техніки тестування засновані на досвіді